How Kubernetes enforces the desired state principle

Desired state is one of the core concepts of Kubernetes. Through a declarative or an imperative API (I will come back to this notion later) you describe the state of the objects (Pod, ReplicatSet, Deployment, …) that will run the containers.
Kubernetes, via the « Kube controller managers » (part of the master components), are in charge of regulating the state of the system. The kubelet component (located on each worker nodes) receives requests and applies the new configuration to run the containers. The state, the configuration, the API Objects,… are stored in a a simple, distributed key value storage : the etcd cluster.
If, due to some failures, the container stops running, the Kubelet recreates the Pod based on the lines of the desired state stored in etcd.
So, Kubernetes strictly ensures that all the containers running across the cluster are always in the desired state.
For instance here is a simple Kubernetes deployment object:
Which is deployed via the following command line:
kubectl apply -f deployment.yamlFrom this very simple exemple several points are really importants.
Deployments (like other objects) within Kubernetes are declarative, so the user specifies the number of instances of a given version of a Pod to be deployed and Kubernetes calculates the actions required to get from the current state to the desired state by deploying or deleting Pods across Nodes.
If you are familiar with Kubernetes config files you already saw the apiVersion and the kind fields at the beginning of each file that describe the object type, its version and group.
It can be confusing, because you will see a lot of different versions like apps/v1beta2, apps/v1, etc. and even without group …
Things are moving really fast in the Kubernetes world, the group notion has been added latter to easily extend the Kubernetes API and break the monolithic API server to smaller components allowing groups to be enabled/disabled …
So, how to know which versions to use?
You just need to ask the API server through the CLI kubectl api-versions:

The semantic for the version and group are well explain in the Kubernetes documentation: https://kubernetes.io/docs/reference/using-api/#api-versioning
and if you want to list the « kind » resources with there related API group juste use kubectl api-resources -o wide
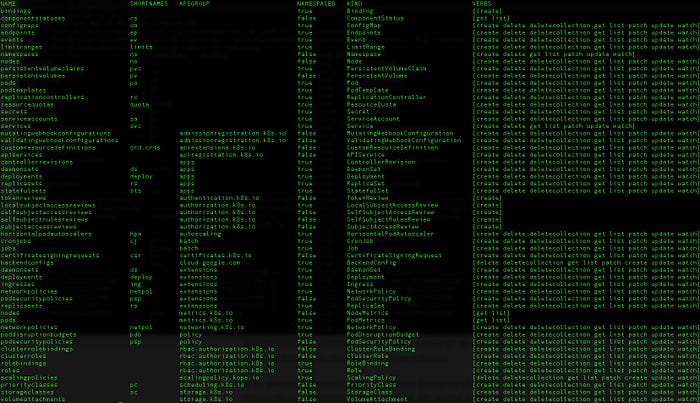
To know the latest supported apiVersion of a resource use the command kubectl explain StatefulSet or check the reference api documentation: https://kubernetes.io/docs/reference/#api-reference
In the previous command I used « -o wide » to display the associated verbs that can be used to interact with the resource. The general style of the Kubernetes API is RESTful — clients create, update, delete, or retrieve a description of an object via the standard HTTP verbs (POST, PUT, DELETE, and GET) — and those APIs accept and return JSON (Kubernetes also exposes additional endpoints for non-standard verbs and allows alternative content types).
If you look under the hood at how various Kubernetes components work, it uses the same API. The control plane (API Server, Controllers, Schedulers, etcd, …) is transparent, as there are no hidden internal APIs
You can easily explore the API used by the CLI by increasing the verbosity:
kubectl get deployments -v=7
and then you can used the same REST URI as shown in the logs to list the deployments using the url :
curl http://localhost:8080/apis/extensions/v1beta1/namespaces/default/deployments?limit=500Tips: To access to a remote Kubernetes API you can use the kubectl proxy commande to acts as a reverse proxy (It will handle the location of the API server and also the authentication) see https://kubernetes.io/docs/tasks/administer-cluster/access-cluster-api/
Having Kubernetes components use the same external API makes Kubernetes composable and extensible.
So Kubernetes can handle declarative an imperative API.
In my first sample I used the declarative approach by creating a yaml file and using the kubectl apply command.
Instead I could have used the imperative way:
kubectl run nginx --image=nginx:1.15.8 --replicas=2 --port=80I definitely recommend to use the first approach. It allows users to commit (in a SCM system) the desired state of the cluster, and to keep track of the different versions, improving auditability and automation through CI/CD pipelines.
Does it mean the imperative API is useless ?
Of course no! There are several use cases where it make sens to use the imperative API.
For instance to query the state of objects, clusters, … It can be used by monitoring tools or for trouble shooting some issues…
Another very practical use case is to use the imperative API for the declarative approach using the--dry-run and the -o yaml options:
kubectl run nginx --image=nginx:1.15.8 --replicas=2 --port=80 --dry-run -o yaml > deployment.yamlusing those options allow to only print the object without sending it.
You can choose the resource type to generate through the--generator option
for instance to generate a pod resource:
kubectl run --generator=run-pod/v1 nginx-pod --image=nginx:1.15.8 --port=80 --dry-run -o yaml > pod.yamlinstead of using the --generator option you can also play with the --restart option (--restart=Never will generate a pod object)
For more information check this page: https://kubernetes.io/docs/reference/kubectl/conventions/
This is a very fast way to « bootstrap » a new Kubernetes object instead of writing yaml file from scratch !
It helps me a lot when I passed the CKAD certification exam.
Conclusion
Declarative configuration management is one of the key strengths of Kubernetes in which you define everything as desired state.
This perfectly matches the GitOps requirements allowing the usage of Git pull requests to manage infrastructure provisioning and software deployment.
This means that both the application and the infrastructure are now versioned artifacts and can be easily audited which is a must have in software development and delivery.
